Version 0.3.1, 12 May 2022
Version history:
0.1, 22 June 2020
- 0.2, 9 August 2021
- 0.3, 9 May 2022
- 0.3.1, 12 May 2022
Scope of this document
The number of linguistics characters in the Unicode Standard is enormous. No attempt is made here to cover all of them. The following are observations of phenomena that have had an impact on Brill’s treatment of linguistic texts. It should be noted that the term ‘linguistics’ can cover the study of specific languages; the study of ‘language’ as such (sometimes called ‘theoretical linguistics’); comparative linguistics; and philology, which is the study of all sorts of language phenomena within the context of traditional scholarly disciplines, such as Classical Studies, theology, Semitic Studies, Arabic Studies, Sinology, and so on.
Distinguishing ‘twins’ typographically
In linguistic representations – specifically IPA, but not limited to that system – two slightly different forms of the same Latin letter represent different phonemes. The following Latin characters are affected: Latin a, f, and g.
Some Greek characters used as phonetic symbols have a distinct ‘Latin’ shape. Most of them now have a Unicode code point of their own, but not all. Therefore, the current version of the Brill fonts (4.00) has the alternate glyph shapes still at their Greek code points but accessible through the OpenType Stylistic Set 20. These are θ and λ. Note that there are also other Latin-shaped Greek characters, among which are β and χ, which have code points of their own (ꞵ and ꭓ).
Because of the subtlety of differences in appearance of these characters it is important to check (or spot-check) these characters by code point. The easiest way to do this in MS Office (Windows) is to copy the character whose Unicode value you wish to know from its source and paste it into a Word document. Once pasted, with the insertion point positioned just after the character in question, type Alt X, which converts the character to its Unicode hexadecimal value (typing Alt X again will toggle this back to the character). On macOS, you can use Character Viewer (sometimes referred to as ‘Emoji & Symbols’): in its Search field, paste the character whose value you wish to determine and it will show the required information instantly next to ‘Unicode’, as a hexadecimal value prefixed with ‘U+’.
For more information, see Using Unicode hexadecimal codes.
Latin twins in the Brill typeface
The letter a can be of the ‘two-storey’ kind, almost always found in serif typefaces; and it can be ‘single-storey’, as in many sans-serif typefaces (this latter, ɑ, is also known as ‘script a’ and ‘Latin alpha’). In serif typefaces, the regular or roman style normally has a two-storey design, whereas the italic is normally of the single-storey kind. In non-technical type it does not matter that the two are sightly different depending on the style.
In linguistic contexts, however, the Latin letters a, f, and g have ‘twins’ with subtly different shapes, and these represent different phonemes. In the table below, in the left-hand column the three Latin pairs of twins are listed:
| Roman | Unicode | Italic | Italic (Stylistic Set 20) |
|---|---|---|---|
| U+0061 | 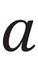 | 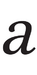 |
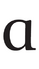 | U+0251 | | ← |
 | U+0066 | 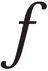 | 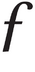 |
 | U+0192 | | ← |
 | U+0067 | 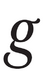 | |
 | U+0261 | ← |
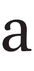
So what should a typesetter do if IPA text is italicised and you want the ‘two-tier’ shape of a to be retained? Apply the OpenType Stylistic Set 20 to the character: this has been programmed into the Brill typeface (The Brill Typeface User Guide, p. 4).
Note: Even when the author has correctly applied the correct OpenType stylistic set to characters listed above, editors must still mark them for the typesetters. The OpenType ss20 attribute does not, unfortunately, carry over to most page layout applications such as Adobe InDesign!
Note also the following concerning the Latin twins mentioned above:
Character | Code point | Name | Remarks |
|---|---|---|---|
| ɑ | U+0251 | Latin alpha or ‘script a’ | There is a capital, Ɑ, U+2C6D, but this forms part of several Cameroon language orthographies, and it is not ordinarily used in strictly linguistic contexts. Note also the existence of ᵅ U+1D45, ɒ U+0252, ᶛ U+1D9B, ꭤ U+AB64, and ꬰ U+AB30. |
ƒ | U+0192 | f with hook or ‘script f’ | Dutch florin (guilder); uppercase is Ƒ, U+0191; do not confuse with lowercase abbreviation is, ꝭ, U+A76D, or with lowercase dotless j with stroke and hook, ʄ, U+0284. |
ɡ | U+0261 | ‘script g’ | IPA voiced velar plosive; uppercase is Ɡ, U+A7AC. |
Greek twins in the Brill typeface
In linguistics, the following Greek letters must take on a special ‘Latin’ shape, and in the Brill typeface these glyph shapes are accessible either via a dedicated Unicode point (which is preferred), or via the OpenType Stylistic Set 20:
| Greek | Unicode | Latin shape (Stylistic Set 20) | Latin shape (Unicode) | Unicode Latin shape |
|---|---|---|---|---|
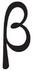 | U+03B2 | (do not use) |
| U+A7B5 |
 | U+03B8 |
| ||
 | U+03BB | 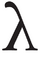 | ||
| U+03C7 | (do not use) |
| U+AB53 |
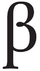

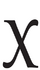
Important note: Even when the author has correctly applied the correct OpenType stylistic set to characters listed above, editors must still mark them for the typesetters, and the latter must be instructed to replace such characters with dedicated characters whenever available, such as in the case of ꞵ and ꭓ (U+A7B5, U+AB53). The OpenType ss20 attribute does not, unfortunately, carry over to most page layout applications such as Adobe InDesign!
Other Latin twins of Greek letters in Unicode
The following Greek letters have Latin twins with Unicode code points of their own, which clearly distinguish them from Greek-language characters. They are used mostly in linguistics contexts, although many of them have subsequently found a place in Latin orthographies of several African languages as well.
| Character | Code point | Name | Remarks |
|---|---|---|---|
| ɑ | U+0251 | Latin alpha or ‘script a’ | There is a capital, Ɑ, U+2C6D, but this forms part of several Cameroon language orthographies, and it occurs but rarely in strictly linguistic contexts. Note also the existence of ᵅ U+1D45, ɒ U+0252, ᶛ U+1D9B, ꭤ U+AB64, and ꬰ U+AB30. |
| ꞵ | U+A7B5 | Latin beta | There is a capital, Ꞵ, U+A7B4, but this forms part of Gabonese orthographies, and it occurs but rarely in strictly linguistic contexts. Note the availability of the Latin glyph shape of Greek beta U+03B2 in the pre-version-4 Brill fonts through application of OpenType ss20. |
| ɣ | U+0263 | Latin gamma | There is a capital, Ɣ, U+0194, but this forms part of some African orthographies, and it occurs but rarely in strictly linguistic contexts. Note also the existence of ˠ U+02E0 Superscript Latin gamma, and ɤ U+0264 ‘Baby gamma’ or ‘ram’s horns’. |
| ẟ | U+1E9F | Latin delta or ‘script d’ or ‘insular d’ | Note also the existence of ƍ U+018D turned delta. |
| ɛ | U+025B | Latin epsilon or ‘open e’ | There is a capital, Ɛ, U+0190, but this forms part of some African (Niger-Congo) orthographies, and it occurs but rarely in strictly linguistic contexts. Note also the existence of ᶓ U+1D93, ɜ U+025C, ᶔ U+1D94, ɝ U+025D, ᶟ U+1D9F, ɞ U+025E, ʚ U+029A, ᴈ U+1D08, ᵋ U+1D4B, and ᵌ U+1D4C. |
| U+03B8 | Latin theta | This character has not yet been encoded in Unicode. The Latin glyph shape of Greek theta U+03B8 in the Brill fonts is accessible by application of OpenType ss20. |
| ɩ | U+0269 | Latin iota | There is a capital, Ɩ, U+0196, but this forms part of some African (Niger-Congo) orthographies, and it occurs but rarely in strictly linguistic contexts. Note also the existence of ᶥ U+1DA5 and ᵼ U+1D7C. Do not confuse with ꙇ Cyrillic iota U+A647. |
| U+03BB | Latin lambda | This character has not yet been encoded in Unicode. The Latin glyph shape of Greek lambda U+03BB in the Brill fonts is accessible by application of OpenType ss20. Note also the existence of ƛ U+019B. | |
| ʊ | U+028A | Latin upsilon | There is a capital, Ʊ U+01B1, but this forms part of some African (Niger-Congo) orthographies, and it occurs but rarely in strictly linguistic contexts. Note also the existence of ᵿ U+1D7F and ᶷ U+1DB7. |
| ɸ | U+0278 | Latin phi | Note also the existence of ᶲ U+1DB2 and ⱷ U+2C77. |
| ꭓ | U+AB53 | Latin khi | Note the availability of the Latin glyph shape of Greek khi U+03C7 in the pre-version-4 Brill fonts through application of OpenType ss20. There is a capital, Ꭓ, U+A7B3, but this is only used in German dialectology. Note also the existence of ꭔ U+AB54 and ꭕ U+AB55. |
| ꞷ | U+A7B7 | Latin omega | There is a capital, Ꞷ, U+A7B6. Both are used in African orthographies. Note also the existence of ɷ U+0277 and ꭥ U+AB65. |
Confusables in linguistics
In linguistics, the following non-literal symbols are often confused:
| WRONG character | Code point | Name | CORRECT character | Code point | Name | Remarks |
|---|---|---|---|---|---|---|
Ø | U+00D8 | Latin capital letter O with stroke | ∅ | U+2205 | Empty set | The ‘empty set’ is used in linguistics to denote a zero morpheme (null morpheme) or zero-grade ablaut (or phonological ‘zero’). Often submitted by authors as Capital letter O with stroke. |
| = | U+003D | Equals sign | ⸗ | U+2E17 | Double oblique hyphen | The ‘double oblique hyphen’ is often used in grammars, as a clitic marker or morpheme boundary marker. Often submitted by authors as Equals sign. |
| “ `` '' " | U+201C U+0060(2×) U+0027(2×) U+0022 | Left double quotation mark; Grave accent(2×); Apostrophe(2×); Quotation mark | ʺ | U+02BA | Modifier letter double prime | To transliterate the Cyrillic hard sign Ъ ъ (capital and lowercase) in the Latin script. Note that the double prime ʺ consists of just one U+02BA character and that this exhibits no casing behaviour. |
| ‘ ` ' | U+2018; U+0060; U+0027 | Left single quotation mark; Grave accent; Apostrophe | ʹ | U+02B9 | Modifier letter prime | To transliterate the Cyrillic soft sign Ь ь (capital and lowercase) in the Latin script. Note that the single prime ʹ U+02B9 exhibits no casing behaviour. |